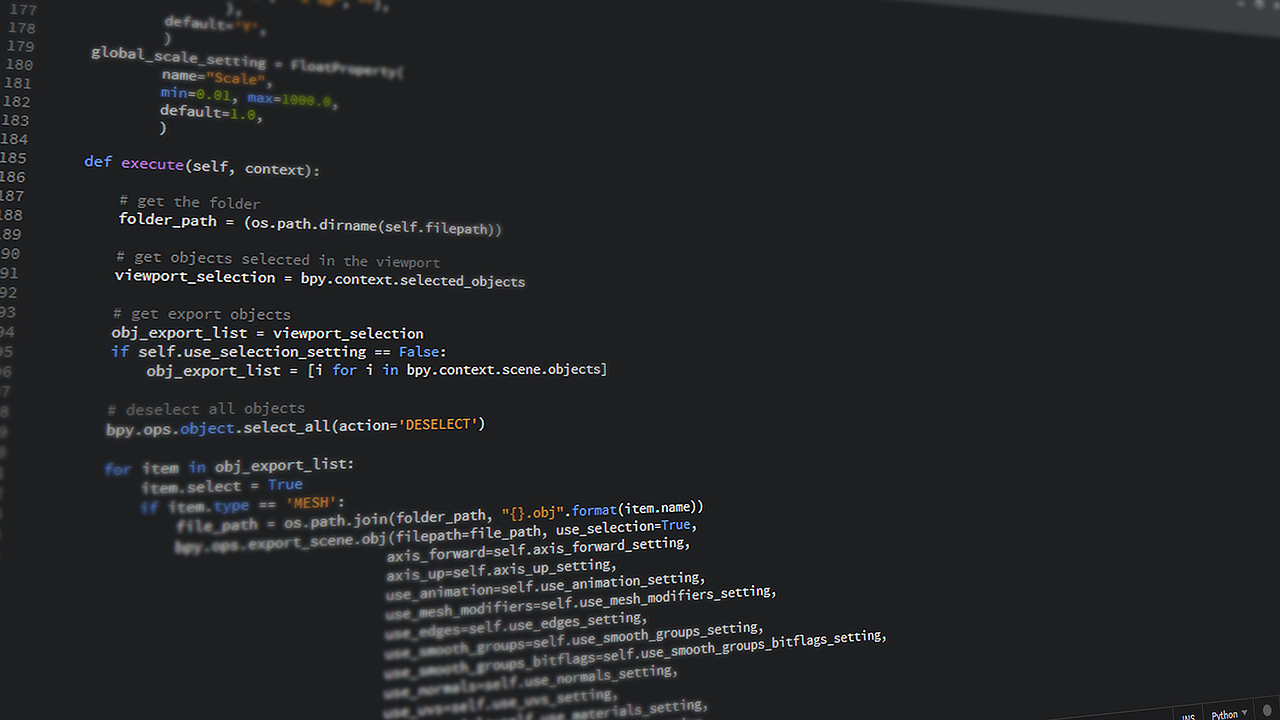
Last week, we used Python libraries to import the data, set the input and out values for the computer to learn, and split the data into groups. Next, we will actually train the computer to learn the relationships. For this, we can use a variety of different tools. While each one has its pros and cons, the novice can simply run each one and determine which one provides the best results. In addition, we will print the results for analysis.
Logistic Regression
# train the model
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
# print accuracy
train_metric = logreg.score(X_train, y_train)
test_metric = logreg.score(X_test, y_test)
print('Accuracy of Logistic regression classifier on training set: {:.2f}'.format(train_metric))
print('Accuracy of Logistic regression classifier on test set: {:.2f}'.format(test_metric))
# print recall
pred = logreg.predict(X_test)
recall_metric = recall_score(y_test, pred, average=recall_average)
precision_metric = precision_score(y_test, pred, average=recall_average)
print('Recall of Logistic regression classifier on test set: {:.2f}'.format(recall_metric))
print('Precision of Logistic regression classifier on test set: {:.2f}'.format(precision_metric))
Decision Tree Classifier
# train the model
clf = DecisionTreeClassifier().fit(X_train, y_train)
# print overall accuracy
train_metric = clf.score(X_train, y_train)
test_metric = clf.score(X_test, y_test)
print('Accuracy of Decision Tree classifier on training set: {:.2f}'.format(test_metric))
print('Accuracy of Decision Tree classifier on test set: {:.2f}'.format(train_metric))
# print recall/precision
pred = clf.predict(X_test)
recall_metric = recall_score(y_test, pred, average=recall_average)
precision_metric = precision_score(y_test, pred, average=recall_average)
print('Recall of Decision Tree classifier on test set: {:.2f}'.format(recall_metric))
print('Precision of Decision Tree classifier on test set: {:.2f}'.format(precision_metric))
Linear Discriminant Analysis
# train the model
lda = LinearDiscriminantAnalysis()
lda.fit(X_train, y_train)
# print overall accuracy
train_metric = lda.score(X_train, y_train)
test_metric = lda.score(X_test, y_test)
print('Accuracy of LDA classifier on training set: {:.2f}'.format(train_metric))
print('Accuracy of LDA classifier on test set: {:.2f}'.format(test_metric))
# print recal
pred = lda.predict(X_test)
recall_metric = recall_score(y_test, pred, average=recall_average)
precision_metric = precision_score(y_test, pred, average=recall_average)
print('Recall of LDA classifier on test set: {:.2f}'.format(recall_metric))
print('Precision of LDA classifier on test set: {:.2f}'.format(precision_metric))
Neural Network
# activation - ‘identity’, ‘logistic’, ‘tanh’, ‘relu’
mlp = MLPClassifier(
hidden_layer_sizes=(512,768,1024,512,128,16)
activation='relu',
learning_rate='adaptive',
max_iter=5000000
)
mlp.fit(X_train,y_train)
# print overall accuracy
train_metric = mlp.score(X_train, y_train)
test_metric = mlp.score(X_test, y_test)
print('Accuracy of Neural Network classifier on training set: {:.2f}'.format(train_metric))
print('Accuracy of Neural Network classifier on test set: {:.2f}'.format(test_metric))
# print recall
pred = mlp.predict(X_test)
recall_metric = recall_score(y_test, pred, average=recall_average)
precision_metric = precision_score(y_test, pred, average=recall_average)
print('Recall of Neural Network classifier on test set: {:.2f}'.format(recall_metric))
print('Precision of Neural Network classifier on test set: {:.2f}'.format(precision_metric))
What We did
You will notice that much of the code above is very similar. This is part of what makes Scikit-Learn such an amazing framework – it’s relatively easy to change between Artificial Intelligence algorithms. In addition to the above algorithms, you can also use Support Vector Machines, Naive Bayes, K-Nearest Neighbor, and many more.
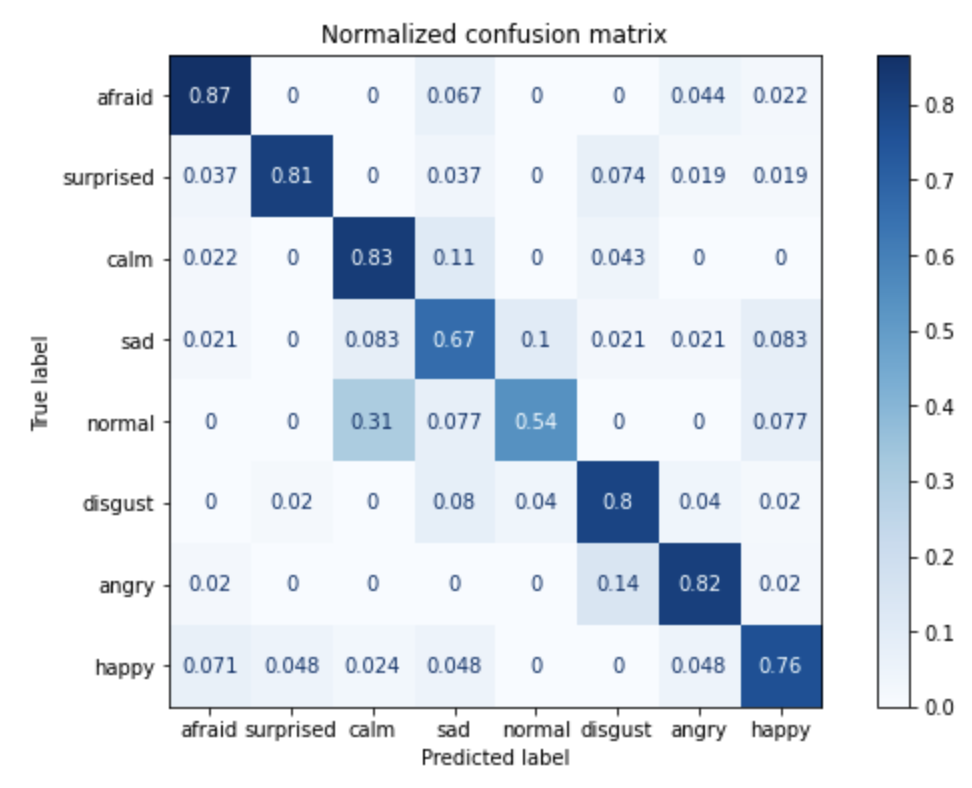
Once you’ve run the training, the scores show how each algorithm performed after it was trained. On any given data set, a different algorithm may work better. This is another benefit to Scikit-Learn – the easy access to a variety of models allows for experimentation to find the best model.
What Next?
While much of underlying math for these algorithms is well outside the scope of knowledge for most, it is useful to understand how Neural Networks operate. They are one of the more interesting implements of AI, and can be tuned to work with lots of data. However, that tuning requires some knowledge of what a Neural Network is and how it works. That’s what we’ll look at next week.